웹이 점점 커지고 다양한 요구가 생겨나는 가운데 NoSQL이 커다란 이슈중에 하나로 떠오르고 있습니다. 제가 NoSQL에 대해서 처음 들은 것은 올 초정도로 기억하고 있습니다.
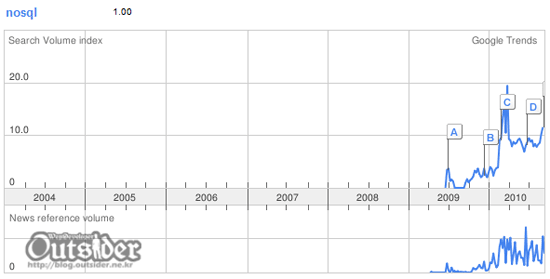
구글 트랜즈 에서 확인해보아도 NoSQL이라는 단어가 이슈화되기 시작한 것은 2009년 중순정도로 나타나고 있습니다. 위키피디아 에서 확인해 보면 NoSQL이라는 단어는 1998년 Carlo Strozzi이 SQL을 드러내지 않는 경량 데이터베이스로 이름지었고 2009년 초에 Last.fm 의 Johan Oskarsson이 오픈소스 분산데이터베이스에 대한 논의를 위한 이벤트를 원했을 때 Rackspace 의 직원인 Eric Evans가 NoSQL이라는 단어를 다시 소개했다고 합니다. 아틀란타에서 열린 no:sql conference 2009가 NoSQL논의에 큰 영향을 미쳤다고 합니다. (이 컨퍼런스의 모토인 "select fun, profit from real_world where relational=false;"가 상당히 센스넘치는군요)
에서 확인해보아도 NoSQL이라는 단어가 이슈화되기 시작한 것은 2009년 중순정도로 나타나고 있습니다. 위키피디아 에서 확인해 보면 NoSQL이라는 단어는 1998년 Carlo Strozzi이 SQL을 드러내지 않는 경량 데이터베이스로 이름지었고 2009년 초에 Last.fm 의 Johan Oskarsson이 오픈소스 분산데이터베이스에 대한 논의를 위한 이벤트를 원했을 때 Rackspace 의 직원인 Eric Evans가 NoSQL이라는 단어를 다시 소개했다고 합니다. 아틀란타에서 열린 no:sql conference 2009가 NoSQL논의에 큰 영향을 미쳤다고 합니다. (이 컨퍼런스의 모토인 "select fun, profit from real_world where relational=false;"가 상당히 센스넘치는군요)
올해 중에 NoSQL중 하나는 경험해 보자는 생각이었는데 마침 좀 만져볼 기회가 생겨서 좀 만져보고 있습니다. 개념자체가 개발자에게 기존에 익숙한 RDBMS와는 너무 달라서 튜토리얼 보고 단순한 사용정도는 할 수 있겠지만 관련해서 고민해 보려면 NoSQL에 대해서 좀 자세히 알아야 할 필요가 있게 느껴졌습니다. 사실 NoSQL에 대한 지식이 많다보니 고민 자체가 해결책이나 진도나 나가지 않고 계속 빙글빙글 도는 느낌이라 여기저기 자료를 좀 찾아서 정리해 보았습니다.
관계형 데이터 베이스는 확장하기가 어렵습니다.
구글 트랜즈
에서 확인해보아도 NoSQL이라는 단어가 이슈화되기 시작한 것은 2009년 중순정도로 나타나고 있습니다. 위키피디아 에서 확인해 보면 NoSQL이라는 단어는 1998년 Carlo Strozzi이 SQL을 드러내지 않는 경량 데이터베이스로 이름지었고 2009년 초에 Last.fm 의 Johan Oskarsson이 오픈소스 분산데이터베이스에 대한 논의를 위한 이벤트를 원했을 때 Rackspace 의 직원인 Eric Evans가 NoSQL이라는 단어를 다시 소개했다고 합니다. 아틀란타에서 열린 no:sql conference 2009가 NoSQL논의에 큰 영향을 미쳤다고 합니다. (이 컨퍼런스의 모토인 "select fun, profit from real_world where relational=false;"가 상당히 센스넘치는군요)올해 중에 NoSQL중 하나는 경험해 보자는 생각이었는데 마침 좀 만져볼 기회가 생겨서 좀 만져보고 있습니다. 개념자체가 개발자에게 기존에 익숙한 RDBMS와는 너무 달라서 튜토리얼 보고 단순한 사용정도는 할 수 있겠지만 관련해서 고민해 보려면 NoSQL에 대해서 좀 자세히 알아야 할 필요가 있게 느껴졌습니다. 사실 NoSQL에 대한 지식이 많다보니 고민 자체가 해결책이나 진도나 나가지 않고 계속 빙글빙글 도는 느낌이라 여기저기 자료를 좀 찾아서 정리해 보았습니다.
CAP Theorem
NoSQL에 대해서 이해하려면 먼저 CAP 이론에 대해서 알 필요가 있습니다. CAP이론은 Brewer's CAP Theorem으로 알려져 있는데 분산 컴퓨팅 시스템에서 보장해야 하는 특징으로 아래 3가지를 정의하고 있습니다.
CAP 이론에 따르면 위 3가지 중에 동시에 2가지만 보장할수 있고 3개를 모두 보장하는 것이 불가능하다고 나와있습니다. 그래서 데이터를 관리할때 이 3가지 중에 어느 2가지에 중점을 두냐는 것은 아주 중요한 부분입니다. 이 부분을 이해하는데 Nathan Hurst이 만든 아래의 Visual Guide to NoSQL Systems 는 큰 도움이 됩니다.

기존에 많이 사용하던 RDBMS는 3가지 중 CA에 집중하고 있습니다. 웹이 발전하면서 다양한 요구사항이 생겨나고 엄청난 양의 데이터를 처리해야 하게 되면서 RDBMS가 갖지 못한 P의 특성이 필요해졌고 그러면서 등장한 것이 NoSQL입니다. 좀더 풀어쓰면 데이터베이스에 대한 수평적 확장(Horizontal Scalability 즉 옆에 서버한대 더 배치해서 데이터베이스를 늘리고 싶다는 의미입니다.)에 대한 이슈가 발생했고 확장성이슈를 해결하기 위해서 P를 선택하다 보니 기존에 가지고 있던 C나 A의 특성중 하나를 포기해야 했습니다. 그래서 NoSQL에는 다양한 시도들이 있지만 가장 중요한 이슈는 확장성을 해결하려는 것으로 생각됩니다.
관계형 데이터베이스는 기본적으로 분산형을 고려해서 디자인 되지 않았습니다. 그래서 ACID(원자성, 일관성, 독립성, 지속성) 트랜잭션 같은 추상화와 고레벨 쿼리모델을 풍부하게 제공할 수 있지만 확장성이 좋지 못하기 때문에 모든 NoSQL 데이터베이스는 다양한 방법으로 확장성 이슈를 해결하기 위해 초점을 맞추고 있습니다. 각 NoSQL에는 여러가지 차이점들이 있지만 CAP의 범주에서만 보면 CP를 선택하거나 AP를 선택하게 됩니다.
왜 비관계형이어야 하는가?
NoSQL이 확장성 이슈를 해결하려고 CP나 AP의 특성을 선택했지만 구체적으로 어떤 특징을 선택하고 왜 그래야 했는지 이해할 필요가 있습니다. NoSQL은 많은 제품군들이 있는데 모두 같은 전략으로 접근하고 있지는 않고 각각에 제품에 따라 다양한 접근을 하고 있는데 아래 적힌 내용들은 비관계형으로 가기 위한 여러가지 특성들에 대한 이야기이고 제품군에 따라 아래의 특성들을 선택한 여부는 다른 것으로 보입니다. 아래의 내용은 상당부분 VINEET GUPTA가 작성한 NoSql Databases - Part 1 - Landscape를 참고하였습니다. 잘 정리된 문서라서 참고하시면 도움이 될 것입니다.
NoSQL에 대해서 이해하려면 먼저 CAP 이론에 대해서 알 필요가 있습니다. CAP이론은 Brewer's CAP Theorem
으로 알려져 있는데 분산 컴퓨팅 시스템에서 보장해야 하는 특징으로 아래 3가지를 정의하고 있습니다.- Consistency (일관성) : 모든 노드들은 동시에 같은 데이터를 보아야 합니다.
- Availability (유효성) : 모든 노드는 항상 읽기와 쓰기를 할 수 있어야 합니다.
- Partition Tolerance (파티션 허용차) : 시스템은 물리적인 네트워크 파티션을 넘어서도 잘 동작하여야 합니다
CAP 이론에 따르면 위 3가지 중에 동시에 2가지만 보장할수 있고 3개를 모두 보장하는 것이 불가능하다고 나와있습니다. 그래서 데이터를 관리할때 이 3가지 중에 어느 2가지에 중점을 두냐는 것은 아주 중요한 부분입니다. 이 부분을 이해하는데 Nathan Hurst
이 만든 아래의 Visual Guide to NoSQL Systems 는 큰 도움이 됩니다.기존에 많이 사용하던 RDBMS는 3가지 중 CA에 집중하고 있습니다. 웹이 발전하면서 다양한 요구사항이 생겨나고 엄청난 양의 데이터를 처리해야 하게 되면서 RDBMS가 갖지 못한 P의 특성이 필요해졌고 그러면서 등장한 것이 NoSQL입니다. 좀더 풀어쓰면 데이터베이스에 대한 수평적 확장(Horizontal Scalability 즉 옆에 서버한대 더 배치해서 데이터베이스를 늘리고 싶다는 의미입니다.)에 대한 이슈가 발생했고 확장성이슈를 해결하기 위해서 P를 선택하다 보니 기존에 가지고 있던 C나 A의 특성중 하나를 포기해야 했습니다. 그래서 NoSQL에는 다양한 시도들이 있지만 가장 중요한 이슈는 확장성을 해결하려는 것으로 생각됩니다.
관계형 데이터베이스는 기본적으로 분산형을 고려해서 디자인 되지 않았습니다. 그래서 ACID(원자성, 일관성, 독립성, 지속성) 트랜잭션 같은 추상화와 고레벨 쿼리모델을 풍부하게 제공할 수 있지만 확장성이 좋지 못하기 때문에 모든 NoSQL 데이터베이스는 다양한 방법으로 확장성 이슈를 해결하기 위해 초점을 맞추고 있습니다. 각 NoSQL에는 여러가지 차이점들이 있지만 CAP의 범주에서만 보면 CP를 선택하거나 AP를 선택하게 됩니다.
왜 비관계형이어야 하는가?
NoSQL이 확장성 이슈를 해결하려고 CP나 AP의 특성을 선택했지만 구체적으로 어떤 특징을 선택하고 왜 그래야 했는지 이해할 필요가 있습니다. NoSQL은 많은 제품군들이 있는데 모두 같은 전략으로 접근하고 있지는 않고 각각에 제품에 따라 다양한 접근을 하고 있는데 아래 적힌 내용들은 비관계형으로 가기 위한 여러가지 특성들에 대한 이야기이고 제품군에 따라 아래의 특성들을 선택한 여부는 다른 것으로 보입니다. 아래의 내용은 상당부분 VINEET GUPTA가 작성한 NoSql Databases - Part 1 - Landscape
를 참고하였습니다. 잘 정리된 문서라서 참고하시면 도움이 될 것입니다.관계형 데이터 베이스는 확장하기가 어렵습니다.
Replication - 복제에 의한 확장
Master-Slave 구조에서는 결과를 슬레이브의 갯수만큼 복제해야 하는데 N개의 슬레이브에서 읽을 수 있기 때문에 Read는 빠르지만 Write에서는 병목현상이 발생하게 기 때문에 확장성에 대한 제한을 가지게 됩니다.
필요없는 특성들
JOIN
데이터가 많을 때 JOIN은 많은 양의 데이터에 복잡한 연산을 수행해야 하기 때문에 비용이 많이 들며 파티션을 넘어서는 동작되지 않기 때문에 피해야 합니다. 정규화는 일관된 데이터를 가지기 쉽게 하고 스토리지의 양을 줄이기 위해서 하는건데 반정규화(De-normalization)를 하면 JOIN문제를 피할 수 있습니다. 반정규화로 일관성에 대한 책임을 디비에서 애플리케이션으로 이동시킬수 있는데 이는 INSERT-only라면 어렵지 않습니다.
ACID 트랜젝션
Atomic (원자성) : 여러 레코드를 수정할 때 원자성은 필요없으며 단일키 원자성이면 충분합니다.
Consistency (일관성) : 대부분의 시스템은 C보다는 P나 A를 필요로 하기 때문에 엄격한 일관성을 가질 필요는 없고 대신 결과의 일관성(Eventually Consistent)을 가질 수 있습니다.
Isolation (격리성) : 읽기에 최선을 다하는(Read-Committe) 것 이상의 격리성은 필요하지 않으며 단일키 원자성이 더 쉽습니다.
Durability (지속성) : 각 노드가 실패했을때도 이용되기 위해서는 메모리가 데이터를 충분히 보관할 수 있을정도로 저렴해지는 시점까지는 지속성이 필요합니다.
어떤 특성들은 갖지 않습니다.
계층화 데이터나 그래프를 모델하는 것은 어렵습니다. 또한 빠른 응답을 위해서 디스크를 피하고 메인 메모리에서 데이터를 제공하는 것이 바람직한데 대부분의 관계형 데이터베이스는 디스크기반이기 때문에 쿼리들이 디스크에서 수행됩니다.
기대하는 특성들
NoSQL이 바라는 환경은 서버들이 다른 용량들을 가지고 수업이 퍼져나가는 것으로 이를 노드라고 부릅니다.
높은 확장성
점진적으로 노드를 추가할 수 있어야 하고 이는 파티셔닝을 통해서 가능합니다.
높은 Availability
실패의 단일포인트가 없으며 데이터는 복제되기 때문에 어떤 노드가 죽었을때도 데이터는 이용이 가능합니다.
높은 성능
디스크대신 메모리 기반으로 결과는 빠르게 리턴되어야 하며 이는 논블락킹 Write와 낮은 복잡성을 가진 알고리즘을 통해서 이룰수 있습니다.
원자성
각각의 쓰기는 원자성을 가질 필요가 있다.
다중 마스터구조에서는 마스터를 추가함으로써 쓰기의 성능을 향상시킬 수 있는데 대신에 충돌이 발생할 가능성이 생기게 됩니다.
Partitioning(Sharding) - 분할에 의한 확장
Read만큼 Write도 확장할 수 있지만 애플리케이션레이어에서 파티션된 것을 인지하고 있어야 합니다. RDBMS의 가치는 관계에 있다고 할 수 있는데 파티션을 하면 이 관계가 깨져버리고 각 파티션된 조각간에 조인을 할 수 없기 때문에 관계에 대한 부분은 애플리케이션 레이어에서 책임져야 합니다. 일반적으로 RDBMS에서 수동 Sharding 은 쉽지 않습니다.
Partitioning(Sharding) - 분할에 의한 확장
Read만큼 Write도 확장할 수 있지만 애플리케이션레이어에서 파티션된 것을 인지하고 있어야 합니다. RDBMS의 가치는 관계에 있다고 할 수 있는데 파티션을 하면 이 관계가 깨져버리고 각 파티션된 조각간에 조인을 할 수 없기 때문에 관계에 대한 부분은 애플리케이션 레이어에서 책임져야 합니다. 일반적으로 RDBMS에서 수동 Sharding 은 쉽지 않습니다.
필요없는 특성들
UPDATE와 DELETE
Update와 Delete는 전통적으로 정보의 손실이 발생하기 때문에 잘 사용되지 않으며 후에 데이터 검사 및 재활성화를 위해서 기록해둘 필요가 있습니다. 그리고 사용자가 커뮤니티를 탈퇴한다고 그들의 글을 지우지 않듯이 도메인 관점에서는 실제로 삭제되지 않습니다. 이런 접근을 하게 되면 Update / Delete를 모두 Insert로 모델할수 있고 과거 데이터는 버전을 붙혀서 기록할 수 있으며 이 데이터들은 비활성데이터들이 됩니다. 이 INSET-only 시스템에서는 2개의 문제가 있는데 데이터베이스에서 종속(cascade)에 대한 트리거를 이용할 수 없으며 Query가 비활성 데이터를 걸러내야 할 필요가 있습니다.
Update와 Delete는 전통적으로 정보의 손실이 발생하기 때문에 잘 사용되지 않으며 후에 데이터 검사 및 재활성화를 위해서 기록해둘 필요가 있습니다. 그리고 사용자가 커뮤니티를 탈퇴한다고 그들의 글을 지우지 않듯이 도메인 관점에서는 실제로 삭제되지 않습니다. 이런 접근을 하게 되면 Update / Delete를 모두 Insert로 모델할수 있고 과거 데이터는 버전을 붙혀서 기록할 수 있으며 이 데이터들은 비활성데이터들이 됩니다. 이 INSET-only 시스템에서는 2개의 문제가 있는데 데이터베이스에서 종속(cascade)에 대한 트리거를 이용할 수 없으며 Query가 비활성 데이터를 걸러내야 할 필요가 있습니다.
JOIN
데이터가 많을 때 JOIN은 많은 양의 데이터에 복잡한 연산을 수행해야 하기 때문에 비용이 많이 들며 파티션을 넘어서는 동작되지 않기 때문에 피해야 합니다. 정규화는 일관된 데이터를 가지기 쉽게 하고 스토리지의 양을 줄이기 위해서 하는건데 반정규화(De-normalization)를 하면 JOIN문제를 피할 수 있습니다. 반정규화로 일관성에 대한 책임을 디비에서 애플리케이션으로 이동시킬수 있는데 이는 INSERT-only라면 어렵지 않습니다.
ACID 트랜젝션
Atomic (원자성) : 여러 레코드를 수정할 때 원자성은 필요없으며 단일키 원자성이면 충분합니다.
Consistency (일관성) : 대부분의 시스템은 C보다는 P나 A를 필요로 하기 때문에 엄격한 일관성을 가질 필요는 없고 대신 결과의 일관성(Eventually Consistent
)을 가질 수 있습니다.Isolation (격리성) : 읽기에 최선을 다하는(Read-Committe) 것 이상의 격리성은 필요하지 않으며 단일키 원자성이 더 쉽습니다.
Durability (지속성) : 각 노드가 실패했을때도 이용되기 위해서는 메모리가 데이터를 충분히 보관할 수 있을정도로 저렴해지는 시점까지는 지속성이 필요합니다.
고정된 스키마
RDBMS에서는 데이터를 사용하기 전에 스키마를 정의해야하고 Index등을 정의해야 하는데 현재의 웹환경에서는 빠르게 새로운 피쳐를 추가하고 이미 존재하는 피쳐를 조정하기 위해서는 스키마 수정이 필수적으로 요구됩니다. 하지만 컬럼의 추가/수정/삭제는 row에 lock을 걸고 index의 수정은 테이블에 락을 걸기 때문에 스키마 수정이 어렵습니다.
RDBMS에서는 데이터를 사용하기 전에 스키마를 정의해야하고 Index등을 정의해야 하는데 현재의 웹환경에서는 빠르게 새로운 피쳐를 추가하고 이미 존재하는 피쳐를 조정하기 위해서는 스키마 수정이 필수적으로 요구됩니다. 하지만 컬럼의 추가/수정/삭제는 row에 lock을 걸고 index의 수정은 테이블에 락을 걸기 때문에 스키마 수정이 어렵습니다.
어떤 특성들은 갖지 않습니다.
계층화 데이터나 그래프를 모델하는 것은 어렵습니다. 또한 빠른 응답을 위해서 디스크를 피하고 메인 메모리에서 데이터를 제공하는 것이 바람직한데 대부분의 관계형 데이터베이스는 디스크기반이기 때문에 쿼리들이 디스크에서 수행됩니다.
기대하는 특성들
NoSQL이 바라는 환경은 서버들이 다른 용량들을 가지고 수업이 퍼져나가는 것으로 이를 노드라고 부릅니다.
높은 확장성
점진적으로 노드를 추가할 수 있어야 하고 이는 파티셔닝을 통해서 가능합니다.
높은 Availability
실패의 단일포인트가 없으며 데이터는 복제되기 때문에 어떤 노드가 죽었을때도 데이터는 이용이 가능합니다.
높은 성능
디스크대신 메모리 기반으로 결과는 빠르게 리턴되어야 하며 이는 논블락킹 Write와 낮은 복잡성을 가진 알고리즘을 통해서 이룰수 있습니다.
원자성
각각의 쓰기는 원자성을 가질 필요가 있다.
지속성
데이터는 휘말성 메모리만이 아닌 디스크에서 유지되어야 합니다.
배포의 유연함(Flexibility)
노드의 추가/삭제는 데이터를 분산하고 수동으로 중재할 필요없이 자동적으로 로드되어야 하며 분산 파일 시스템이나 공유스토리지 요구같은 제약이나 특수한 하드웨어같은 것이 필요없어야 합니다. 이기종간의 하드웨어에서 동작가능해야 합니다.
모델링의 유연함(Flexibility)
Key-Value쌍, 계층형 데이터, 그래프등 여러가지 타입의 데이터를 간단하게 모델할 수 있어야 합니다.
쿼리의 유연함(Flexibility)
하나의 호출에서 제공된 키에 대한 값이 묶음을 얻는 다중 GET과 키의 특정 범위에 기반한 데이터를 얻는 범위 쿼리가 필요합니다.
데이터는 휘말성 메모리만이 아닌 디스크에서 유지되어야 합니다.
배포의 유연함(Flexibility)
노드의 추가/삭제는 데이터를 분산하고 수동으로 중재할 필요없이 자동적으로 로드되어야 하며 분산 파일 시스템이나 공유스토리지 요구같은 제약이나 특수한 하드웨어같은 것이 필요없어야 합니다. 이기종간의 하드웨어에서 동작가능해야 합니다.
모델링의 유연함(Flexibility)
Key-Value쌍, 계층형 데이터, 그래프등 여러가지 타입의 데이터를 간단하게 모델할 수 있어야 합니다.
쿼리의 유연함(Flexibility)
하나의 호출에서 제공된 키에 대한 값이 묶음을 얻는 다중 GET과 키의 특정 범위에 기반한 데이터를 얻는 범위 쿼리가 필요합니다.
이 포스팅은 NoSQL에 대해서 #2로 이어집니다.
Footnote.
- Read-Your-Writes(RYW) 일관성은 레코드가 업데이트 되었을때 그 레코드에 대한 읽기시도는 업데이트된 값을 돌려주는 것을 보장해주는 것의 의미합니다. [Back]
2010/09/18 23:57 2010/09/18 23:57
'Database' 카테고리의 다른 글
| DROP, DELETE, TRUNCATE의 차이점 (0) | 2011.06.29 |
|---|---|
| NoSQL에 대해서 #2 (0) | 2011.06.09 |