전화번호부
전화번호를 찾는 패턴을 살펴볼까요? :
이렇게 하면 다음 전화번호 같은 거 쉽게 찾습니다.
032-812-6333
헷갈리지 마세요. '-' 문자는 [] 안에서만 특별한 의미가 있습니다.
근데 지역번호가 항상 0으로 시작하더라... 따라서 123-812-6333 같은건 가짜더라...라고 판단이 되면...:
로 바꿔주면...
132-812-6333
이런건 가짜라서 안찾습니다. 쉽지요?
눈치 빠른 분들은 웹사이트 등에서 이메일이나 전화번호, 계좌번호 같은 일정한 틀이 있는 입력항목을 어떻게 확인하는지(validation) 아시겠지요? 대부분 regex를 씁니다. 주어진 regex 패턴을 통과하지 못하면 이메일 주소가 올바르지 않습니다 라는 오류 메시지가 나오는거지요:-)
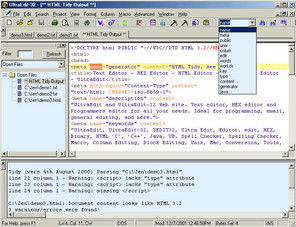
HTML 소스에서 태그 날리기
이것도 쉽습니다. 아무 웹페이지나 가서 HTML 소스 하나 가져오세요. 그걸 울트라 에디터에서 보세요. 거기서 태그만 다 날리고 실제 웹에서 보는 문자들만 남기고 싶다... 어떻게 할까요?
regex 모르면 역시 맨땅에 헤딩입니다. 게다가 손으로 하면 실수하기 쉽구요. 이렇게 하면 끝납니다:
<html>, </html> 식의 태그만 쏙쏙 뽑아 몽땅 날려줍니다. < 로 시작하고 중간에 어떤 문자(.)가 몇번 반복되건(*) 상관없고 끝나는것만 > 로 끝나면 된다...니까요.
근데 문제가 있습니다. . 패턴은 줄바꿈 문자는 찾지 않거든요. 그래서 태그가 길어져 다음 줄로 넘어간건 못찾습니다:
식의 태그 말입니다. regex는 art라고 했습니다. 마술을 부려 봅시다:
쬐끔 복잡하지요? 근데 역시 < 로 시작해 > 로 끝나는 문자의 연속이라는 패턴은 같습니다. [^<>] 가 헷갈릴 지 모르지만 어떤 문자라도, 심지어 줄바꿈 등 특수문자가 계속되도 상관없지만 단, < 라는 문자와 > 라는 문자만 없으면 된다는 의미거든요.
그러니 줄바꿈이 들어가 잘려진 태그도 찾아내서 날려보내 줍니다. 예술이지요?
진짜 실험해 보세요. 아무리 복잡한 HTML 소스라도 깔끔히 정리해줍니다.
이메일 주소만 찾기
쬐끔 어려운 거 해보고 끝내겠습니다. 더 지겨워들 하기전에 :-)
이메일 추출기 원리입니다. 아니 사실 나쁜데 쓰지 않으면 거의 중급 수준의 regex로 이정도면 여러분 웬만한 문서 작업에서는 남들보다 날라다닐 수 있을 겁니다:
이메일만 잡아냅니다. @ 를 좌우로 해서 _ 나 -, . (이스케이프를 시켜줘야 regex에서 쓰는 특별한 의미가 아닌 문자 그대로의 의미로 받아들임) + 문자나 숫자로 반복되는 문자열을 양쪽으로 잡아내는 겁니다.
지금 해보세요. 이 문서에도 이메일이 몇개 있습니다. 그거 다 잡습니다. 쬐끔 응용을 하면...:
골뱅이 양쪽 문자열을 괄호로 감싸줬지요? 이걸 바꾸기에 응용하는 겁니다. 모든 이메일 주소를 spam 에 악용되지 않게 wankyuchoi@gmail.com 이라는 건 wankyuchoi at gmail.com 식으로 사람이 읽듯 바꿔줘 버리는 겁니다.
겁나게 쉽습니다:
\1 은 첫번째 괄호 결과값 \2 는 두번째 괄호 결과값이라고 했지요? (이런식 표현은 9개까지 가능합니다. 1,2,3,4,5,6,7,8,9... 괄호를 아홉개까지 써서 바꾸기에 응용한다는 거지요. 9개까지 쓸 수 있으면 여러분도 regex 아띠스뜨~ 입니다.)
한번 해보세요. 응용 패턴 2를 찾기 상자에 넣고 바꾸기 패턴을 바꾸기 상자에 넣고 몽땅 바꾸기 말고 하나씩... 그럼 어떻게 바뀌는지 보일겁니다.
예를 들어 게시판에 있는 모든 글속의 이메일 주소를 이런식으로 바꾸라고 윗사람이 생 난리를 친다... 그 사람 regex 라는 거 모른다... 그럼 한 한달 걸리는 걸로 안다... 그럼 한 10초 해서 바꿀 거 생각하고 1달 휴가 갔다 오면 된단 말입니다. 글고 나서, "부장님 저 엄청 뺑이쳤어요... 글이 좀 많아야지요..." 해 보세요.
그럼 "진짜 수고했어..." 그럴겁니다. :-)
그럼 http://www.google.com 이나 ftp://ftp.google.com 식은? :
역시 쉽지요? 알파벳 문자열의 연속(http, ftp) + :// + 공백이아닌([^ ]) 문자열의 연속(+) :
http:// 를 ftp:// 로 바꾸고 싶다... 바꾸기에서 ftp\1 이렇게 해주면 되겠지요?
역시 눈치 빠른 분들은 뭔가 번뜩이는게 있을 겁니다. HTML anchor 태그도 쓰지 않았는데 게시판 같은 프로그램을 보면 간단히 URL만 적어도 링크를 자동으로 걸어주지요? 웬만한 게시판들에는 이 기능이 있습니다. 어떻게 하는 걸까요? 예, regex 입니다.
그만 쓸랍니다. 더 나가면 저나 여러분 모두 돌아버릴 것 같아서... :-)
컴퓨터의 노예가 되지 말자
우리 모두 알고 살았으면 합니다. 모르면 수족이 고생이라는 게 맞는 말이더라구요. 정말 주변에 그런 일 많이 봤습니다. 몇년전에 어쩌다 친구 사무실 놀러갔는데 그 놈이 글쎄 한달동안 문서 작업했다고 뭔가 보여주더군요. 몇백 페이지짜리 문서를 공백만 딜리트키 엄청 누르면서 줄맞추고...
눈물이 앞을 가렸습니다. 안타까움에 부둥켜 안고 펑펑 울고 싶었습니다. 한달... 아깝지 않아요? 부모님 묘를 찾지 못해 묘앞의 팻말을 몽땅 뽑아와서 낭패를 본 까망눈 아저씨를 보고 눈물을 흘리던 윤봉길의 마음이었습니다. 윤봉길 의사가 독립운동을 시작한 이유라고 하지요.
그러지 말자구요.
한가지는 명심하자구요. 컴퓨터 만든 놈들은 알게 모르게 귀찮은 거, 단순 반복 겁나게 싫어하는 놈들입니다. 그래서 단순반복 맨땅 헤딩 이런거 안하려고 무지 많은 걸 만들어 놨습니다.
뭔가 이건 인간이 할 짓이 아닌 거 같은데... 로보트 없나? 라는 생각이 드는 무식한 작업이 있으면... 분명 딴 방법이 있습니다.
여러분이 다음에 해당한다면 다시 생각하고 조금만 배워서 활용하고, 그 낭비할 시간에 휴가 가서 재충전하고 옵시다.
- del 키나 backspace 를 1분 이상 반복적으로 눌러댄 적이 있다.
- abc 순으로 줄을 정렬하느라 대가리 뽀개진 적이 있다. ( 실제로 이런 사람 많습니다. 정렬이 뭔지 몰라서... )
- 한 문서에서 하던 일을 또 다른 문서에서 똑같이 하며 "에이, !@$!@#!@$#@$... 이런 단순 무식한 일을 시키고 #$#@$ 이야..." 라고 푸념한 적이 있다.
끝으로.. 걍... 아무도 관심 없으실 수도 있지만... 쩌기 regex에 덧붙여 쬐끔만 프로그래밍, 아니 스크립팅을 배우면 regex로 벌 수 있는 정신적 육체적 시간 X 100 배의 효과를 낼 수 있습니다.
프로그램 아무나 하나...
예, 아무나 합니다. 딴 놈들도 다 그렇게 아무나 하는 줄 알고 시작한 거구, 저도 그랬구요. 앞에 말한 100배 라는 시간... 사실 그런 기초적인 것까지는 1주일이면 배우거든요.
여러분... 컴터의 노예가 되지 말고 부려 먹읍시다.
여러분은 일을 시키는 입장이어야 합니다. 일은 컴터가 해야 하구요. del 키 열라 누르는건... 일은 여러분이 하고 컴퓨터는 노는 겁니다.
명령 하나 때리고 커피 마실때 컴퓨터 혼자 땀 삐질삐질 흘리며 뭔가 일할때... 비로소 여러분은 그 컴퓨터의 master이고 컴퓨터는 slave가 되는 겁니다.
기계의 노예가 되지 맙시다.
우리나라에서 컴퓨터를 소지한 여러분들이 이정도만 아신다고 해도... 우리나라 경쟁력은 하늘을 찌르지 않을까... 또라이같은 생각도 해봅니다.
Regex 에 대해 더 배우고 싶으신 분이 계시면 다음 책 사서 읽어보세요. 단, 번역서 사지 마세요^^ 이유는 짐작하실겁니다.
아마존에 있고 우리나라 컴퓨터 원서 파는 대부분 대형 서점에 있습니다.
더 이상의 regex 책은 없다고 해도 과언이 아닙니다.
Mastering Regular Expressions by Jefferey E.F. Friedl - O'Reilly and Associates, Inc.

[출처] 1주일 할일을 10초만에 하는 비법 전수 - 제 5 부 |작성자 대두족장
'Etc' 카테고리의 다른 글
| 인터넷익스플로러 여러버전 동시 사용 (0) | 2011.04.18 |
|---|---|
| 정규식 강좌 (0) | 2011.04.06 |
| 1주일 할일을 10초만에 하는 비법 전수 - 제 4 부 (0) | 2011.04.06 |
| 1주일 할일을 10초만에 하는 비법 전수 - 제 3 부 (0) | 2011.04.06 |
| 1주일 할일을 10초만에 하는 비법 전수 - 제 2 부 (0) | 2011.04.06 |