내 블로그나 홈페이지에 검색엔진을 장착해 보고 싶다면 엔진으로 스핑크스(Sphinx)를 선택해보는 것도 좋을 것 같습니다. 오픈 소스이고 PHP, Perl, C/C++, 등의 프로그래밍 언어 API 를 제공하고 있으므로 PHP 로 개발된 텍스트큐브와 같은 설치형 블로그에 검색을 붙이려면 PHP 용 API 를 이용하며 될 것입니다. 이미 텍스트큐브에도 검색이 있지만 레코드수가 많아서 검색해야할 항목이 많아질 경우 검색 시간이 많이 소요되고 복잡한 조건의 검색을 할 수 없는 문제가 있습니다. 개발언어를 다룰 수 있다는 조건 하에 스핑크스 검색엔진을 사용해볼 것을 권해봅니다.
스핑크스 검색엔진이 어떤 것인지 체험 해보려면 간단히 아래에 설명하는 방법으로 설치하고 테스트 해보면 됩니다. 참고로 리눅스 CetOS 5.x 에서 테스트 되었습니다. 물론 소스 코드가 공개 되어 있으므로 윈도우즈와 다른 리눅스, 유닉스 계열 OS 를 사용할 수 있습니다.
| [root@sphinx ~]# yum -y install mysql-devel [root@sphinx ~]# cd /usr/local/src [root@sphinx src]# wget http://www.sphinxsearch.com/downloads/sphinx-0.9.8.1.tar.gz [root@sphinx src]# tar xvzf sphinx-0.9.8.1.tar.gz [root@sphinx src]# cd sphinx-0.9.8.1 [root@sphinx sphinx-0.9.8.1]# ./configure [root@sphinx sphinx-0.9.8.1]# make [root@sphinx sphinx-0.9.8.1]# make install |
위와 같이 설치하면 아래와 같은 스핑크스 관련 파일들이 기본 폴더(/usr/local/bin)에 설치됩니다.
/usr/local/bin/indexer
/usr/local/bin/searchd
/usr/local/bin/search
/usr/local/bin/spelldump
또한 아래와 같은 설정 파일 샘플과 MySQL 용 SQL 샘플이 설치됩니다.
/usr/local/etc/sphinx.conf.dist
/usr/local/etc/sphinx-min.conf.dist
/usr/local/etc/example.sql
MySQL 에 접속해서 테스트용 데이타베이스(test) 를 만들고 user 와 password 를 만들고 이 데이타베이스(test)에 권한을 부여 합니다. test로 데이타베이스를 정할 경우 이미 생성되 있으므로 권한 부여만 합니다.
| [root@sphinx sphinx-0.9.8.1]# mysql -uroot -p Enter password: ******** Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 116 Server version: 5.0.45 Source distribution Type 'help;' or 'h' for help. Type 'c' to clear the buffer. mysql> grant all privileges on test.* to user@"localhost" identified by "password"; Query OK, 0 rows affected (0.05 sec) mysql> flush privileges; Query OK, 0 rows affected (0.01 sec) mysql> exit Bye [root@sphinx sphinx-0.9.8.1]# |
데이타베이스 설정이 완료 되었으면 스핑크스 셋팅 파일을 만들어줍니다.
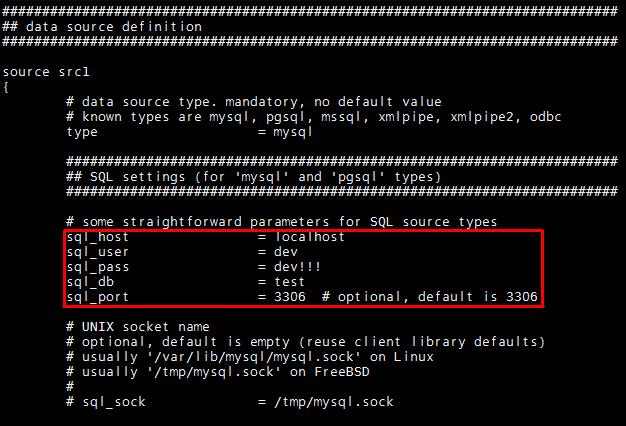
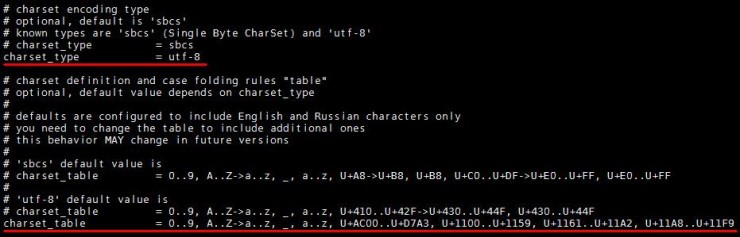
| [root@sphinx sphinx-0.9.8.1]# vi /usr/local/etc/sphinx-min.conf.dist [root@sphinx sphinx-0.9.8.1]# cp /usr/local/etc/sphinx-min.conf.dist /usr/local/etc/sphinx.conf [root@sphinx sphinx-0.9.8.1]# cat /usr/local/etc/sphinx.conf # # Minimal Sphinx configuration sample (clean, simple, functional) # source src1 { type = mysql sql_host = localhost sql_user = user sql_pass = password sql_db = test sql_port = 3306 # optional, default is 3306 sql_query = SELECT id, group_id, UNIX_TIMESTAMP(date_added) AS date_added, title, content FROM documents sql_attr_uint = group_id sql_attr_timestamp = date_added sql_query_info = SELECT * FROM documents WHERE id=$id } index test1 { source = src1 path = /var/data/test1 docinfo = extern charset_type = sbcs } indexer { mem_limit = 32M } searchd { port = 3312 log = /var/log/searchd.log query_log = /var/log/query.log read_timeout = 5 max_children = 30 pid_file = /var/log/searchd.pid max_matches = 1000 seamless_rotate = 1 preopen_indexes = 0 unlink_old = 1 } [root@sphinx sphinx-0.9.8.1]# |
나 의 데이타베이스 설정에 맞게 위와 같이 설정이 완료되면 아래와 같이 스핑크스에서 제공하는 샘플 테이블을 MySQL 에 만들어줍니다. 그리고 커멘드라인 프로그램 indexer 를 실행해서 검색을 위한 인덱스를 생성합니다. 인덱싱이 완료 되면 커멘드라인 프로그램 search 를 실행해서 검색을 할 수 있습니다.
| [root@sphinx sphinx-0.9.8.1]# mysql -uroot -p test < /usr/local/etc/example.sql Enter password: ******** [root@sphinx sphinx-0.9.8.1]# mkdir /var/data [root@sphinx sphinx-0.9.8.1]# indexer test1 [root@sphinx sphinx-0.9.8.1]# search number Sphinx 0.9.8.1-release (r1533) Copyright (c) 2001-2008, Andrew Aksyonoff using config file '/usr/local/etc/sphinx.conf'... index 'test1': query 'number ': returned 3 matches of 3 total in 0.000 sec displaying matches: 1. document=1, weight=1, group_id=1, date_added=Sat Dec 6 11:42:12 2008 id=1 group_id=1 group_id2=5 date_added=2008-12-06 11:42:12 title=test one content=this is my test document number one. also checking search within phrases. 2. document=2, weight=1, group_id=1, date_added=Sat Dec 6 11:42:12 2008 id=2 group_id=1 group_id2=6 date_added=2008-12-06 11:42:12 title=test two content=this is my test document number two 3. document=4, weight=1, group_id=2, date_added=Sat Dec 6 11:42:12 2008 id=4 group_id=2 group_id2=8 date_added=2008-12-06 11:42:12 title=doc number four content=this is to test groups words: 1. 'number': 3 documents, 3 hits [root@sphinx sphinx-0.9.8.1]# |
위와 같이 인덱싱이 완료되고 search 커멘드라인 명령어를 이용해 "number" 라는 검색어(키워드)로 검색하면 검색결과 3개의 문서가 검색되었다고 알려줍니다.
PHP 로 검색엔진을 제어하기 위해 아래와 같이 검색 데몬(searchd)을 띄우고 PHP 용 API 를 이용해서 검색할 수 있습니다.
| [root@sphinx sphinx-0.9.8.1]# /usr/local/bin/searchd Sphinx 0.9.8.1-release (r1533) Copyright (c) 2001-2008, Andrew Aksyonoff using config file '/usr/local/etc/sphinx.conf'... creating server socket on 0.0.0.0:3312 [root@sphinx sphinx-0.9.8.1]# cd api [root@sphinx api]# php test.php number Query 'number ' retrieved 3 of 3 matches in 0.000 sec. Query stats: 'number' found 3 times in 3 documents Matches: 1. doc_id=4, weight=100, group_id=2, date_added=2008-12-06 11:42:12 2. doc_id=1, weight=1, group_id=1, date_added=2008-12-06 11:42:12 3. doc_id=2, weight=1, group_id=1, date_added=2008-12-06 11:42:12 [root@sphinx api]# |
위 와 같이 검색 데몬 searchd 를 띄우고 샘플 PHP 소스 파일 test.php 를 실행하면 검색 결과를 확인할 수 있습니다. 샘플 소스 상단을 보면 sphinxapi.php 라는 파일을 Include 합니다. 이것이 PHP 용 API 입니다.
간단하게 스핑크스를 설치하고 테스트도 해봤습니다. 이제 내 블로그 데이터를 인덱싱하고 이를 검색할 수 있도록 검색 페이지를 만드는 일만 남았습니다.
오픈 소스 검색 엔진 스핑크스(Sphinx) 홈페이지
- http://www.sphinxsearch.com/
스핑크스(Sphinx)로 PHP로 커스텀 검색 엔진 구현하기
- http://www.ibm.com/developerworks/kr/library/os-php-sphinxsearch/index.html
'Search Engine > Sphinx' 카테고리의 다른 글
| 스핑크스 설정 (0) | 2012.06.05 |
|---|---|
| [설치/설정] 검색엔진]sphinx quick start (0) | 2012.02.13 |
| sphinx 검색엔진 한글 검색 설정 (0) | 2012.02.13 |
| 스핑크스(sphinx) 검색 엔진 reindex (1) | 2012.02.13 |
| 스핑크스(sphinx) 검색엔진 설치 및 유니코드 셋팅 (0) | 2012.02.13 |