1. 서론
스핑크스(sphinx) 1.x 버전에서 부터는 RT Index를 지원을 해주고 있다. 하지만 설명에서 이것저것 지원이 안되는 기능들이 좀 있는 것 같아 merging index를 테스트 해보기로 했다. 이 부분 또한 사이트(http://www.sphinxsearch.com)에 설명이 되있다. 하지만 이거 하면서 삽질한것들을 나중에 사이트만 보고 다시 하게 되면 또 할듯 해서 이렇게 글로 남겨 놓는다.
2. 목적
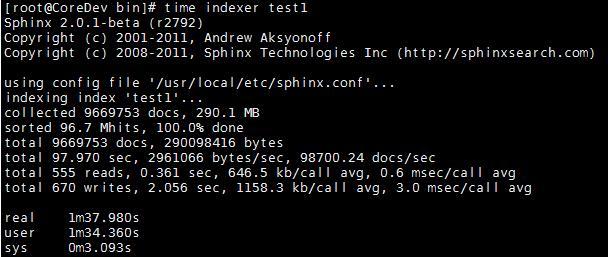
documents라는 테이블에 100개의 row가 존재한다고 해보자. 우리는 이 100개의 row를 indexing해서 search 하게 될것이다. 그런데 여기서 추가적으로 10개의 데이터가 들어와 총 데이터가 110개가 됐을 경우를 생각해 보자. 이 경우 우리는 어떻게 해야 할까? 새롭게 Indexing을 해야 할까? 지금 예를 든것과 같이 데이터가 작을 경우는 문제가되지 않겠지만 데이터가 900만건 정도 되는 큰 데이터일 경우 상당한 문제가된다. 대략 1분 40초 가량의 인덱싱 시간을 소비하게 되는데 이걸 매번 할수는 없는 일이다. 비용적으로 말이 안된다. 그렇기 때문에 ReIndexing이 필요하다.
3. 테이블 정보 셋팅
사이트에 보면은 main과 delta 라는 인덱스를 생성하고 delta라는 인덱스를 이용해 main에 최신 데이터를 갱신해 주게끔 설명이 되있어 설명에 따라 테스트를 진행했습니다.
테이블 정보(스핑크스 샘플 및 사이트의 예제를 통해 만든 테이블) :
document_counter(counter_id,max_doc_id)
documents(id, group_id, group_id2, date_added, title, content)
1) document_counter의 경우 main 인덱스가 인덱싱한 documents의 마지막 id 값을 가지게 됩니다.
2) documents의 경우는 실질적인 데이터를 가지게 됩니다.
4. sphinx.conf 셋팅
config 파일의 경우 내용이 좀 길어서 첨부하겠습니다. 그리고 필요한 부분만 따로 글로 옮기겠습니다.
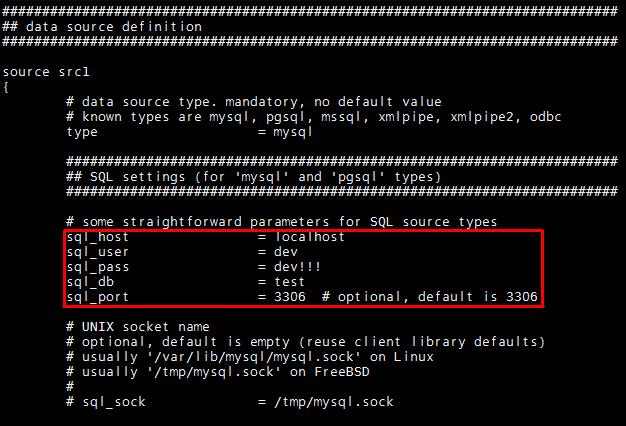
- source main
이곳에서는 쿼리만을 보면 될듯 합니다.
그리 어렵지 않으니 한번 보면 알수 있을듯 합니다.
우선 REPLACE INTO 부분을 보시게되면은 documents에 id의 max값을 구해 document_counter에 넣어주는것을 볼수 있습니다. 이것은 아래 sql_query를 보면은 왜 이렇게 하는지 알수 있을 겁니다. 결국 main의 인덱싱 되는 데이터의 범위를 정해주는 역할을 합니다.

- source delta : main
delta의 경우 main을 상속(?) 받습니다. 상속이라는 말이 맞는지 모르겠습니다. 하지만 여기서도 쿼리를 구성해서 실행을 하게 됩니다. 아래의 그림의 쿼리를 보게되면 main과 반대로 새로 들어온 데이터를 로드해오는것을 알수 있습니다. 결국 delta의 경우 최신 데이터를 가지고 있게 됩니다.

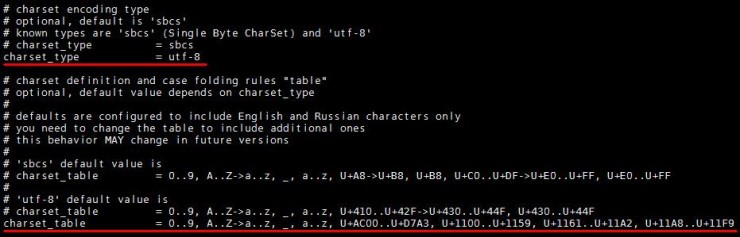
중요한 부분은 여기까지입니다 그리고 나머지는 index 부분이 있는데 이 부분은 경로 및 charset_ 등을 셋팅해주는 작업이니 첨부된 config 파일을 보시면 알수 있을 듯 합니다.
5. 사용
config가 셋팅이 됐다면 이제 해야 할 일은 indxer를 이용해 인덱싱 하는 일만 남았습니다.
bash$ indexer main
bash$ indexer delta
데이터를 삽입 후
bash$ indxer delta
bash$ indexer --merge main delta --rotate
※ 저 같은 경우 위의 경우를 하는데 에러가 나서 한참 삽질을 했는데요. 결국 원인은 config 셋팅 문제 였습니다. 만일 안된다고 하시면 config 셋팅 부분을 다시 한번 살피시는게 좋을듯 합니다.
위와 같이 indexer를 이용해 merge 한 후 search를 이용해 검색을 하게 되면 아래와 같이 main과 delta 두 군데에서 결과를 얻을수 있게 됩니다. 만약 데이터가 한쪽에만 있다고하면 한쪽에서 검색이 됩니다.

이게 스핑크스(sphinx)에서 말하는 분산 인덱스 기능인듯 합니다. 여러개로 인덱스를 나눠 놓고 search를 할 경우 searchd에서 알아서 여러개의 인덱스 파일에서 데이터를 match 시켜 찾는 겁니다. 분산처리를 하게 될 경우 매우 유용할듯 하지만 현재 테스트 중인 저에게는 그다리 필요가 없네요^^;
6. 마치며
config 셋팅 때문에 삽질좀 했습니다. 테스트 할것들이 한두개가 아닌데 테스트 할 부분 정리를 하다가 갑자기 reindexing이 생각이 나서 찾아서 만들어 본다는게 시간이 꾀 걸렸네요. 이 다음에는 시스템 리소스를 얼마나 효율적으로 사용을 할수 있는지 조사를 해봐야 할듯 합니다. 이 부분 빨리 테스트를 진행하고 api를 활용해서 검색 부분을 만들어봐야 할듯 합니다.
[출처] 스핑크스(sphinx) 검색 엔진 reindex|작성자 권상택
'Search Engine > Sphinx' 카테고리의 다른 글
| 스핑크스 설정 (0) | 2012.06.05 |
|---|---|
| [설치/설정] 검색엔진]sphinx quick start (0) | 2012.02.13 |
| Sphinx (0) | 2012.02.13 |
| sphinx 검색엔진 한글 검색 설정 (0) | 2012.02.13 |
| 스핑크스(sphinx) 검색엔진 설치 및 유니코드 셋팅 (0) | 2012.02.13 |